
Physical AI Can’t Exist Without Eyes: Why Visual Tech Is the Real Engine Behind the Machines
/
CEO Jensen Huang Keynote at CES 2025 ©NVIDIA
The world’s first mobile robot to combine perception, reasoning and action, Shakey the Robot, was developed by the Stanford Research Institute between 1966 and 1972. At the time, and for several decades following, the capabilities of computer science and artificial intelligence limited the potential for a machine to see, understand and act on the world. In the past decade, we have witnessed how AI can be applied to cloud servers, video calls & chatbots. As AI lives within robots, vehicles and machines that perceive, predict, and move, vision is paramount. Physical AI – machines that interact with the physical world – cannot succeed without seeing the physical world first.
Every robot, drone, self-driving car, delivery bot, and surgical assistant that claims “intelligence” is fundamentally a product of visual and/or electromagnetic perception systems. The success of Physical AI doesn’t start with neural networks or GPUs – it starts with cameras, sensors, and spectral scanners that give machines their first sense of reality.
Physical AI will not succeed until machines can truly see. Since 2012, we have had the same thesis investing in people building businesses powered by visual technology & AI. In order for machines to perform like humans, or better than humans and truly address our needs – they need to capture, analyze and learn from visual data.
We can’t have intelligent robots, autonomous vehicles, or embodied systems without the ability to capture, interpret, and act upon visual and electromagnetic data. Intelligence without perception is hallucination.
The foundation of Physical AI is not only code or compute – vision, code & compute are essential pillars.
Seeing Is Surviving: The Visual Foundation of Physical AI
When companies like OpenAI, Tesla, and Boston Dynamics discuss embodied intelligence, they are really talking about perception. A machine can only act intelligently when it sees and understands its environment in high-fidelity detail.
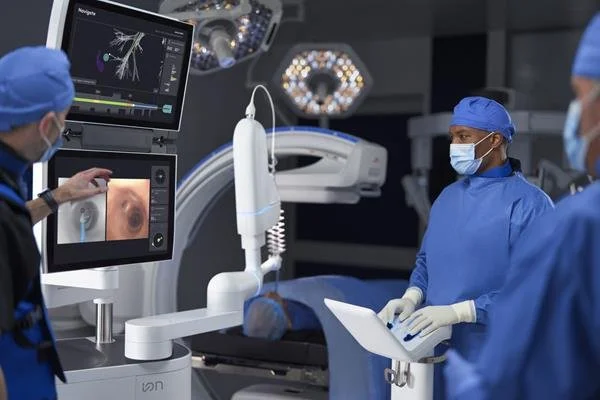
Intuitive recently expanded AI and advanced imaging integration in the Ion endoluminal system. ©Intuitive
Consider Tesla’s Full Self-Driving (FSD) system. While neural networks often dominate the headlines, the real breakthrough came from its eight-camera surround-vision setup – with no radar – relying on electromagnetic modeling to interpret a chaotic world of motion, light, and uncertainty. Vision, not just software, enables the car to perceive the subtleties of its environment: lane markings, pedestrians, unpredictable weather.
Or take Agility Robotics’ Digit, the humanoid loader used in warehouses. Digit doesn’t just walk; it climbs stairs, balances boxes, and navigates complex terrain – thanks to a blend of depth cameras, LiDAR, and inertial sensors. The robot’s neural network doesn’t make movement decisions in isolation; it waits for its “visual cortex” – the sensor array – to map reality in real time.
Even in medicine, Intuitive Surgical’s da Vinci robot depends on stereoscopic cameras that deliver sub-millimeter 3D depth to surgeons. AI’s role in assisting is only possible because vision supplies precise context. Without imaging, physical AI is just a motorized algorithm swinging in the dark.
"Until a robot can truly see – understanding depth, motion, and the space around it – it’s operating blind. Vision is the gateway to meaningful autonomy. Without that spatial perception, every decision it makes risks being inaccurate or incomplete,” says Jan Erik Solem, co-founder & CEO of Staer. Jan Erik is a LDV Capital Expert in Residence and we were the first investor in his last company Mapillary which was acquired by Facebook.
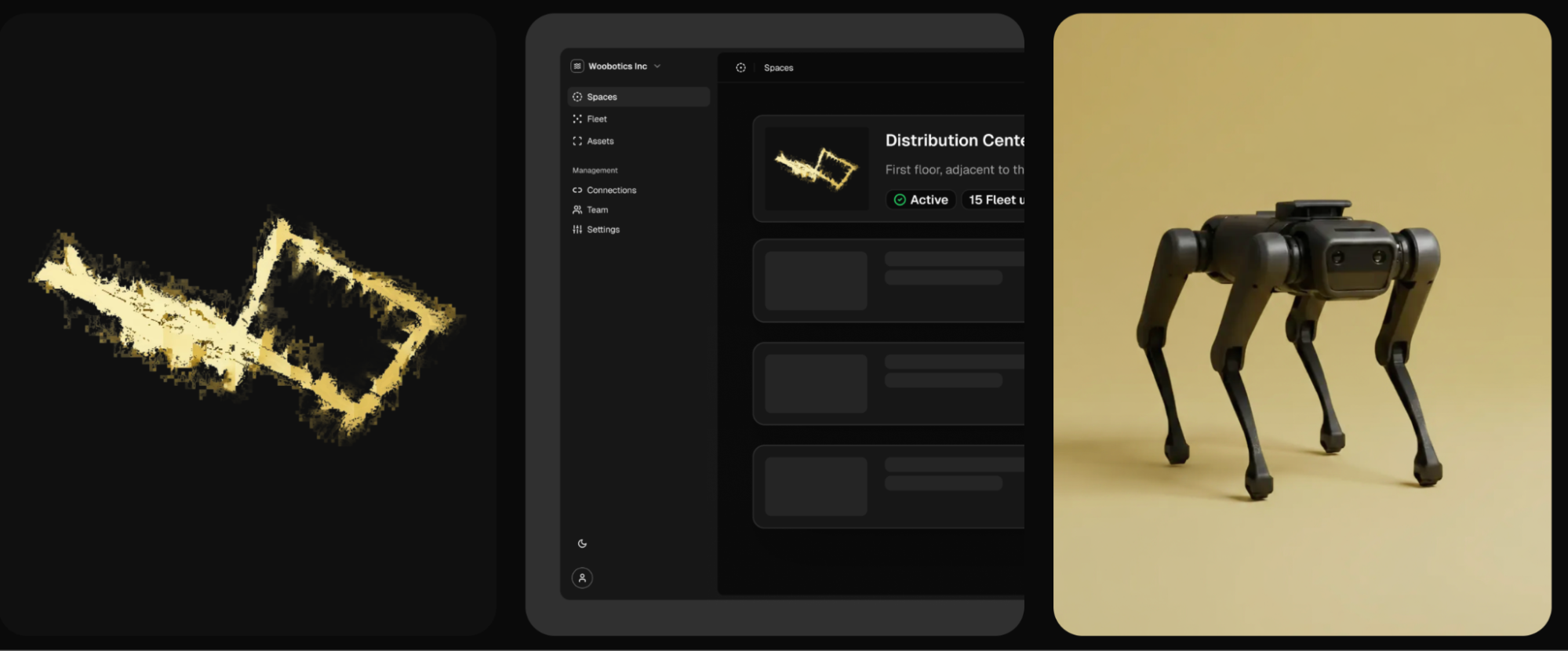
Staer’s platform creates semantic 3D maps, continuously updated across all mobile robots. ©Staer
Jan Erik spoke at our inaugural LDV Vision Summit in 2014, and we are thrilled to welcome him back at our 12th Annual LDV Vision Summit on March 11, 2026, to discuss with Evan Nisselson the integration of AI with physical systems like robotics and autonomous vehicles, a major trending topic driven by its rapidly expanding applications in manufacturing, logistics and other industries. RSVP to secure your free ticket.
Electromagnetic Empathy: Beyond the Visible Spectrum
Machine vision is not limited to the same light that humans see. Visual tech includes seeing the Invisible Data as well. Physical AI leverages multispectral and hyperspectral imaging, teaching machines to detect what our eyes miss: chemical signatures, moisture gradients, temperature shifts, and even biological markers.
In agriculture, defense, or healthcare, these systems are already revealing hidden insights. Synthetic-aperture radar (SAR) enables drones and satellites to peer through clouds, smoke, or even the earth’s surface. In hospitals, thermal cameras, ultrasound patches, and other electromagnetic sensors provide continuous, non-invasive scanning.

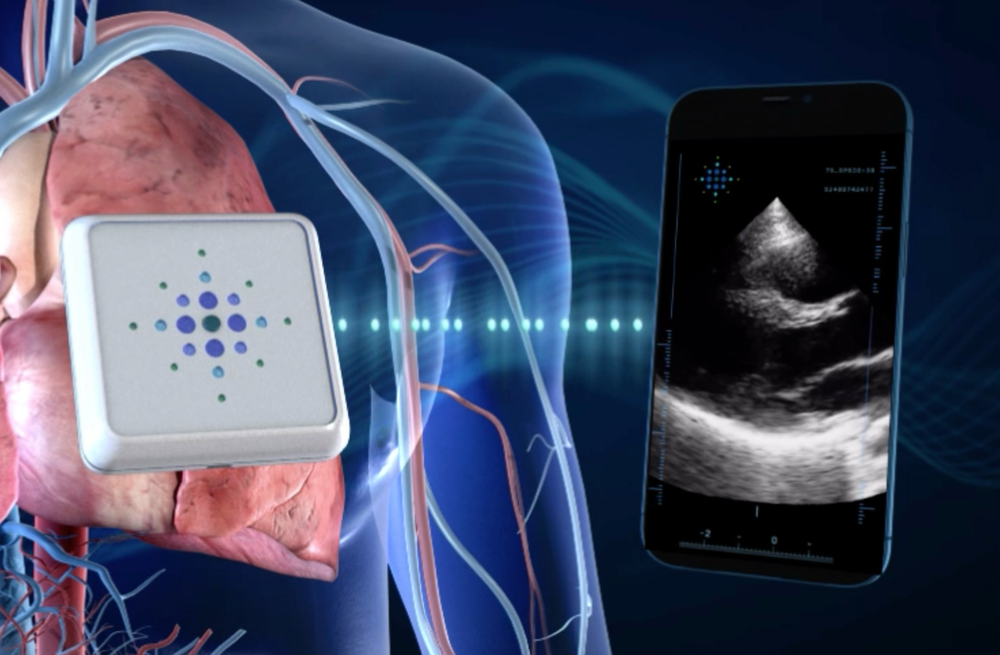
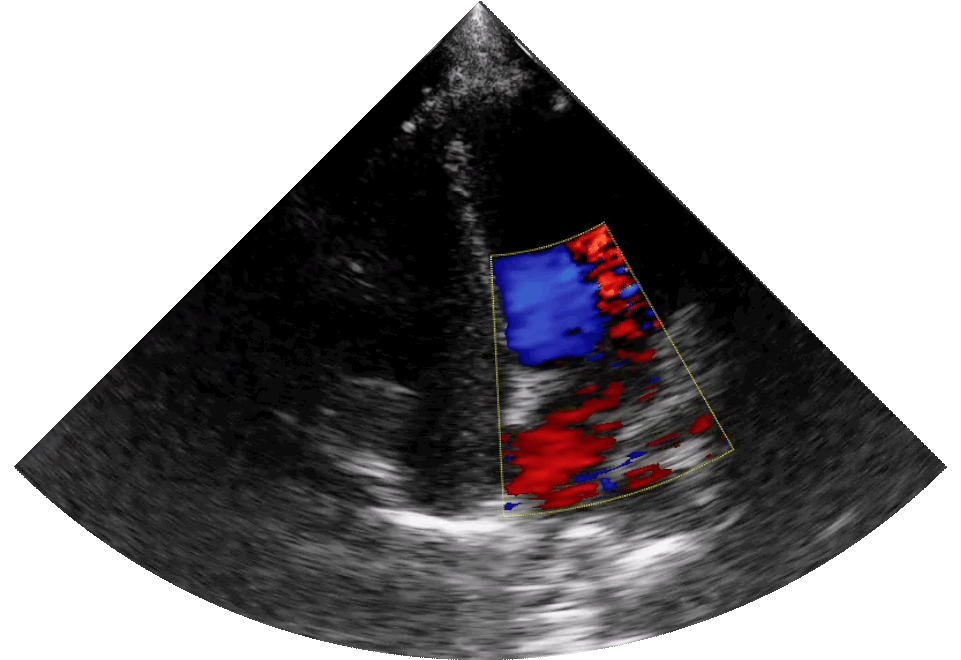
The next generation of ultrasound technology, delivering remote diagnostic imaging. This multispectral “sixth sense” fuses data from different wavelengths into a rich, actionable awareness. ©Sonus Microsystems
When sensors detect temperature anomalies such as in facial cues or chemical fingerprints of materials analysis, AI doesn’t just “see” – it understands. This layered perception becomes the lifeblood of physical AI, enabling machines to operate in domains that are invisible to the human eye.
"Physical AI, truly autonomous robotic systems are different from the robots of the past in one critical dimension, perception. These systems need a model of the world in the loop of their decision making. That external understanding can only be built through sensing. Now we're seeing autonomous systems with multi-modal sensing. Vision, combined with lidar and even imaging radars are used to fill the gaps in what robots can see around them," said Tom Galluzzo, robotics leader and serial entrepreneur. At our 6th Annual LDV Vision Summit, he gave a keynote titled “How Will Robots With Eyes Transform Logistics?”
From Perception to Action: The Feedback Loop of Intelligence

GTC March 2025 Keynote with NVIDIA CEO Jensen Huang showcased a collaboration with Cadence and Boeing. Cadence's "physical AI" refers to using artificial intelligence to enhance physical simulations for product design, a concept being developed through collaborations with companies like NVIDIA and a recent acquisition of Hexagon's design and engineering business. This initiative aims to accelerate complex engineering workflows for industries such as aerospace and automotive, enabling customers like Boeing to achieve faster design cycles, improved performance and more efficient, data-driven simulations. ©NVIDIA
The real intelligence of physical AI emerges when visual data triggers physical action, creating a continuous feedback loop.
In manufacturing, computer vision algorithms identify defective parts on a conveyor belt, triggering instant micro-adjustments in robotic arms.
In autonomous drones, visual SLAM (Simultaneous Localization and Mapping) calculates flight paths and avoids obstacles on the fly.
In smart cities, traffic cameras powered by neural nets dynamically adjust signal timing, optimizing flow in real time.
This is not science fiction – it's the staging of a next-generation economy. Vision in all its spectral richness becomes the most valuable input for intelligence systems. Perceptual Dominance controls the sensors, data streams, and analysis layers that let machines make meaning from photons, particles, and patterns.
“The move to general purpose robotic applications is dependent on the machine understanding the dynamics of the physical world – light, weight, heat, dimensionality, viscosity. Whether through real world or simulated data we are now able to train robots with such information and enable them to do more than humans alone can do. We have clearly gone beyond the LLMs of the purely digital world,” says William O’Farrell, founder & CEO of SceniX.ai. He brought four companies from formation through exit (one IPO) – all of which developed deep tech, cutting-edge technological products.
The Hands Problem: Unlocking Degrees of Freedom
Physical AI must also manipulate – and here, the so-called “hands problem” remains a critical barrier. As The Wall Street Journal recently pointed out, creating robotic hands that match the dexterity, force sensitivity, and feedback of human hands is one of the biggest technical hurdles facing the humanoid revolution.

XPeng develops its own humanoid robot, the IRON, and partners with NVIDIA for both its electric vehicles and some of its robotics development. This example was part of of NVIDIA CEO Jensen Huang Keynote at CES 2025 ©NVIDIA

NVIDIA Isaac™ GR00T ©NVIDIA. Jan Kautz, VP of Learning & Perception Research at NVIDIA, spoke about Gr00T and NVIDIA’s new simulation and generative AI tools at our 11th Annual LDV Vision Summit.
NVIDIA Isaac GR00T N1, announced in March, 2025, is the world’s first open foundation model for humanoid robotics. GR00T N1 employs a dual-system architecture inspired by human cognition. Its “System 1” is fast and reflexive, trained on human demonstrations and synthetic data. Its “System 2” is deliberative and structured, using a vision-language-action (VLA) model to plan and reason. Developers can post-train GR00T N1 with real or simulated data, adapting it to different humanoid bodies and tasks.
That being said, in the human hand, there are dozens of degrees of freedom, intricate joints, and dense sensor networks – all wrapped in soft, responsive tissue. Replicating that in metal, motor, and skin-like materials has proven fiendishly difficult. And yet, without that dexterity, robots remain limited, relegated to grippers, simple pinching mechanisms, or industrial clamps.
Researchers are trying different solutions – from four-fingered tactile hands to three-fingered grippers – each design balancing strength, agility, and resilience. But the tradeoffs are real: adding sensors increases cost; increasing flexibility reduces durability; more motors mean more complexity and energy consumption.
This mechanical challenge – coupled with the perceptual and control loops – is why general-purpose humanoids are being held back from becoming a revolution.
The next trillion-dollar companies will be born at the intersection of visual sensing, physical data, haptics and intelligent autonomy.
Physical AI depends on vision the way the internet depends on connectivity. It’s the prerequisite for everything else.
That’s why forward-looking capital is already flowing into the technologies that make machines aware: multispectral sensors, vision-first robotics, real-time 3D capture, and synthetic training data. These are not niche subcategories – they are the backbone of the embodied AI revolution.
Every machine that sees the world more clearly will move through it more intelligently. The ‘Internet of Eyes’ article I wrote in 2016 expanded on how this will shape the world.
To build the next generation of Physical AI – robots that build, heal, protect, and explore – we’ll need a revolution not just in computation but in sensing technologies.
When these sensing modalities converge, we’ll give machines not just vision, but awareness and ability to act similar to humans. That’s when Physical AI truly becomes galvanized.
“We’re entering an era where sensing is no longer a peripheral capability – it’s the core of machine intelligence,” says Dr. Serge Belongie, Professor of Computer Science at the University of Copenhagen, Director of the Pioneer Centre for Artificial Intelligence and LDV Capital Expert in Residence. “As robots begin to fuse vision, depth, and spectral signals into a coherent understanding of their surroundings, we can progress beyond ‘Dataset AI’ into the era of Embodied AI. That fusion of sensing technologies is what transforms a machine from a tool into a perceptive collaborator.” At out 11th Annual LDV Vision Summit, Dr. Belongie covered major computer vision & machine learning trends: from autoregressive token prediction to agentic AI, physics engines and more.
Physical AI is the embodiment of data – it’s what happens when software gets eyes, ears, and reflexes. But we shouldn’t confuse cognition with perception. The smartest model in the world can’t fix a bolt, perform a surgery, or deliver a package if it can’t see where it’s going.
As the next wave of machines enters our homes, hospitals, factories, and cities, remember: before intelligence comes sight.
Physical AI isn’t about teaching machines to think – it’s about teaching them to see.
We are thrilled to invite you to our 12th Annual LDV Vision Summit (virtual) on March 11, 2026!
We’re thrilled to announce the first few speakers:



An entrepreneur, engineer and artist, Dr. Catie Cuan is a pioneer in the nascent field of “choreorobotics” and works at the intersection of artificial intelligence, human-robot interaction and art. She is currently building a new company in the robotics space.
Dick Costolo is the Managing Partner and Co-Founder of 01 Advisors. Prior to 01 Advisors, Dick was CEO of Twitter from 2010 to 2015, having joined the company as COO in 2009. During his tenure, he oversaw major growth and was recognized as one of the 10 Most Influential U.S. Tech CEOs by Time. Before Twitter, Costolo worked at Google following its acquisition of FeedBurner.
Dr. Jan Erik Solem, CEO and co-founder of Stær, is building robots that are truly autonomous, able to map new environments, understand space, plan their movements and continuously improve. Most recently, Dr. Solem was director of engineering for Maps at Meta following the company’s 2020 acquisition of his startup Mapillary, where LDV was the first investor.
Join our free event to be inspired by cutting-edge computer vision, machine learning and AI solutions that are improving the world we live in!